Attaching package: 'rpart'
The following object is masked from 'package:dials':
prune
library("rpart.plot")library("glmnet")
Loading required package: Matrix
Attaching package: 'Matrix'
The following objects are masked from 'package:tidyr':
expand, pack, unpack
Loaded glmnet 4.1-7
library("ranger")library(vip)
Attaching package: 'vip'
The following object is masked from 'package:utils':
vi
# Fix the random numbers by setting the seed # This enables the analysis to be reproducible when random numbers are used set.seed(123)# Put 70/30 of the data into the training set data_split <-initial_split(FinalDataML, prop =7/10)# Create data frames for the two sets:train_data <-training(data_split)test_data <-testing(data_split)# Create data frames for the two sets:train_data <-training(data_split)test_data <-testing(data_split)#5-fold cross-validation, 5 times repeatedfold_ds<-vfold_cv(train_data, v =5, repeats =5, strata = BodyTemp)#Recipe for the data and fitting data_recipe <-recipe(BodyTemp ~ ., data = train_data) %>%step_dummy(all_nominal(), -all_outcomes()) null_recipe <-recipe(BodyTemp ~1, data = train_data) %>%step_dummy(all_nominal(), -all_outcomes()) #linear modelln_model <-linear_reg() %>%set_engine("lm") %>%set_mode("regression")#Workflownull_flow <-workflow() %>%add_model(ln_model) %>%add_recipe(null_recipe)#look at modelnull_fit <- null_flow %>%fit(data=train_data) %>%fit_resamples(resamples=fold_ds)
! Fold1, Repeat1: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold2, Repeat1: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold3, Repeat1: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold4, Repeat1: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold5, Repeat1: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold1, Repeat2: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold2, Repeat2: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold3, Repeat2: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold4, Repeat2: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold5, Repeat2: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold1, Repeat3: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold2, Repeat3: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold3, Repeat3: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold4, Repeat3: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold5, Repeat3: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold1, Repeat4: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold2, Repeat4: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold3, Repeat4: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold4, Repeat4: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold5, Repeat4: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold1, Repeat5: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold2, Repeat5: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold3, Repeat5: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold4, Repeat5: internal: A correlation computation is required, but `estimate` is constant and ha...
! Fold5, Repeat5: internal: A correlation computation is required, but `estimate` is constant and ha...
# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 rmse standard 1.22 25 0.0178 Preprocessor1_Model1
2 rsq standard NaN 0 NA Preprocessor1_Model1
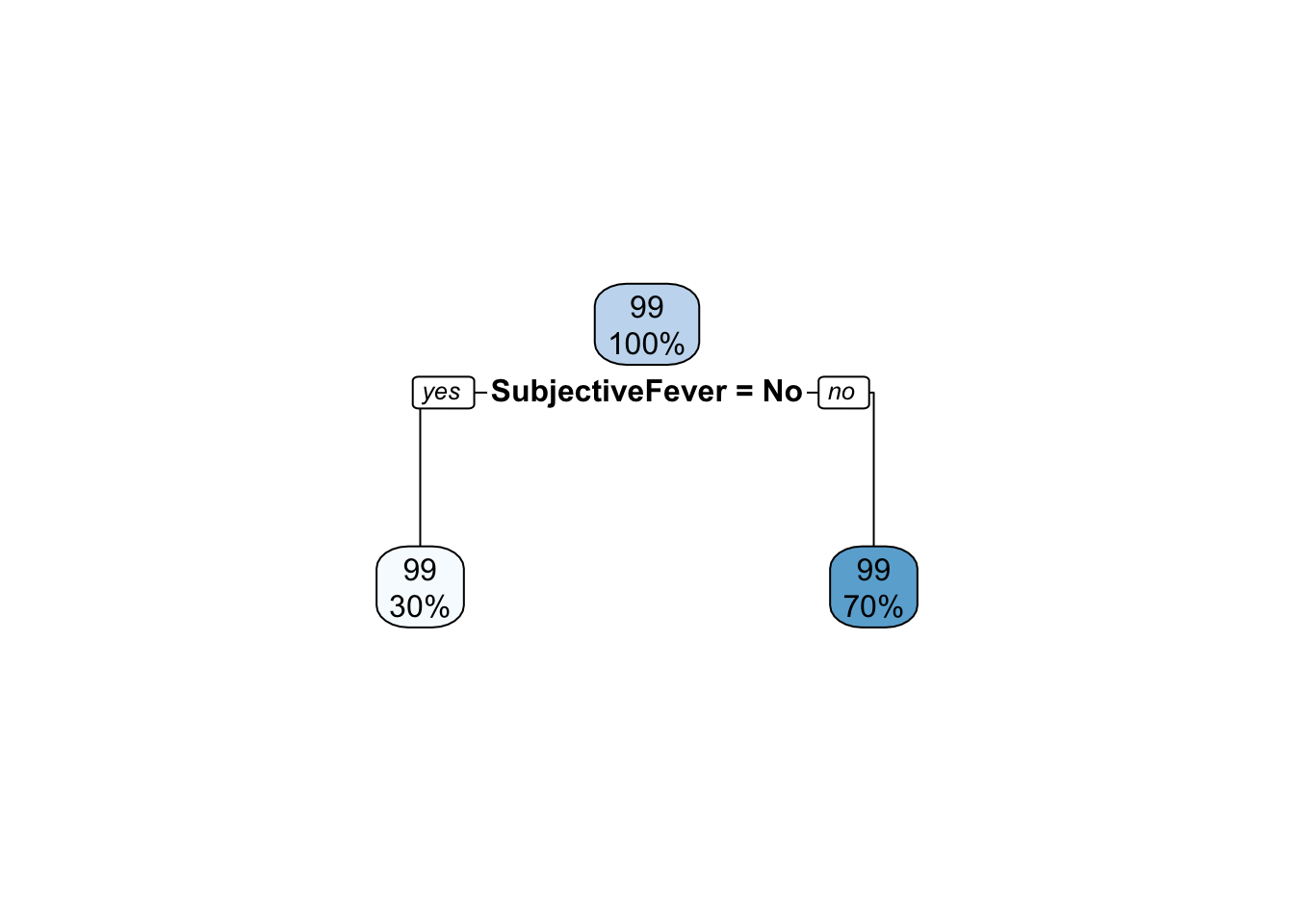
#Plot final fitrpart.plot(extract_fit_parsnip(final_fit)$fit)
Warning: Cannot retrieve the data used to build the model (so cannot determine roundint and is.binary for the variables).
To silence this warning:
Call rpart.plot with roundint=FALSE,
or rebuild the rpart model with model=TRUE.
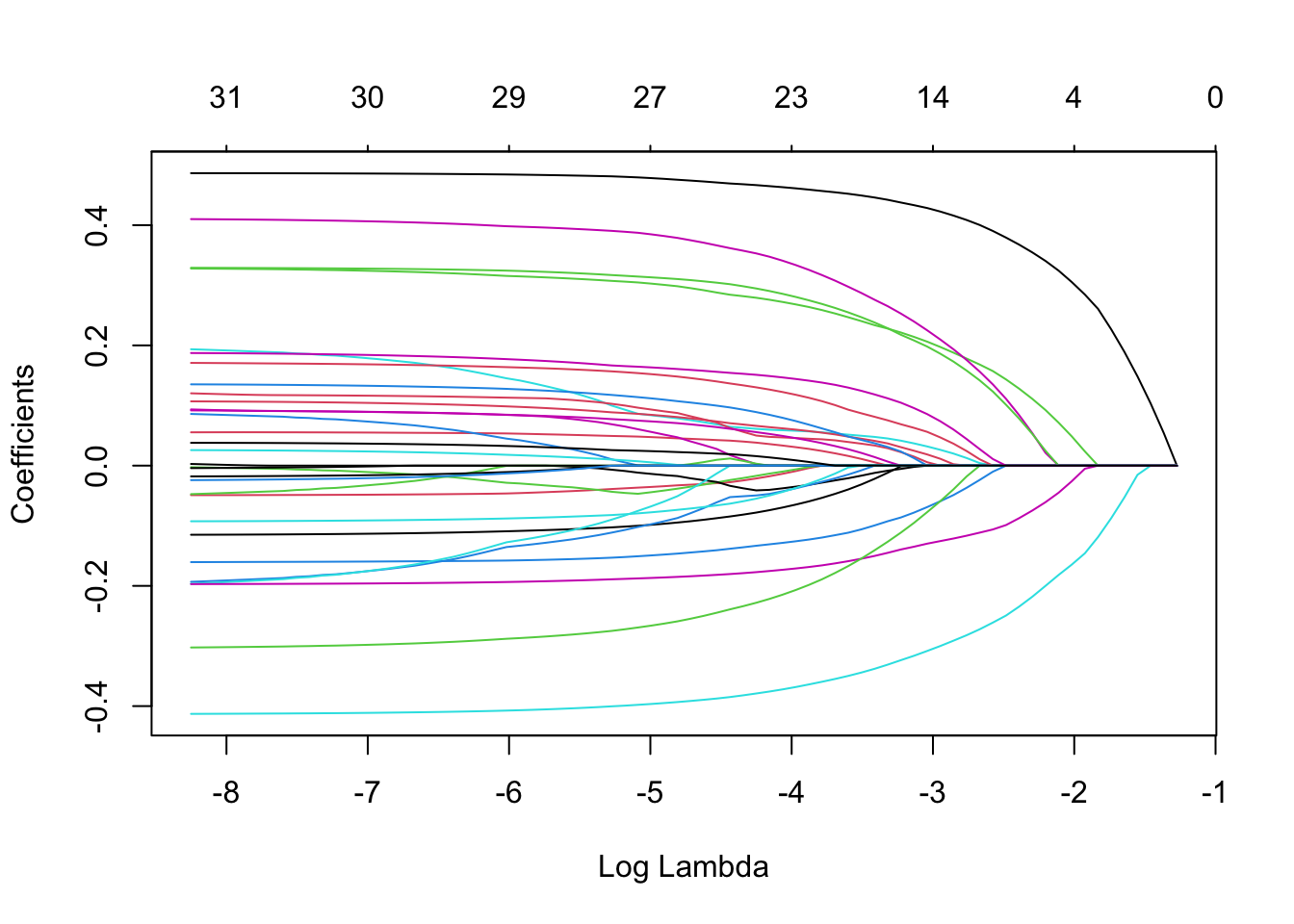
Lasso
#The steps (block of code) you should have here are 1) model specification, 2) workflow definition, 3) tuning grid specification and 4) tuning using cross-validation and the tune_grid() function.#Build modellasso_mod <-linear_reg(penalty =tune(), mixture =1) %>%set_engine("glmnet")#Create workflow using data recipe from abovelasso_workflow <-workflow() %>%add_model(lasso_mod) %>%add_recipe(data_recipe)# tuning gridlasso_grid <-tibble(penalty =10^seq(-4, -1, length.out =30))#Bottom 5 penalty valueslasso_grid %>%top_n(-5)
#The steps (block of code) you should have here are 1) model specification, 2) workflow definition, 3) tuning grid specification and 4) tuning using cross-validation and the tune_grid() function.#Build cores <- parallel::detectCores()cores
Collection of 2 parameters for tuning
identifier type object
mtry mtry nparam[?]
min_n min_n nparam[+]
Model parameters needing finalization:
# Randomly Selected Predictors ('mtry')
See `?dials::finalize` or `?dials::update.parameters` for more information.